





DeepSeek 开源周day1 推出FlashMLA! 专为Hopper 架构 GPU打造的超高效 MLA (Multi-Layer Attention) 解码内核,现在已经正式开源啦!

什么是 FlashMLA?
简单来说,FlashMLA就是一个为了让 英伟达Hopper架构 GPU跑得更快更溜的MLA 解码加速器! 它主要针对变长序列 (variable-length sequences)的场景进行了深度优化,尤其是在大模型推理服务中,效率提升简直肉眼可见!
根据官方介绍,FlashMLA 目前已经在生产环境中使用,稳定性杠杠的!
FlashMLA 有啥亮点? ✨
•✅ BF16 精度支持:紧跟潮流,支持最新的 BF16 精度,性能与效率兼得!
•✅ Paged KV Cache (页式键值缓存):采用页式 KV 缓存,块大小为 64,更精细的内存管理,效率更高!
•⚡️ 极致性能:在H800 SXM5GPU 上,内存受限场景下可达3000 GB/s的惊人速度,计算受限场景也能达到580 TFLOPS的算力! 而且,这一切都基于CUDA 12.6实现的!
快速上手,体验飞一般的感觉!
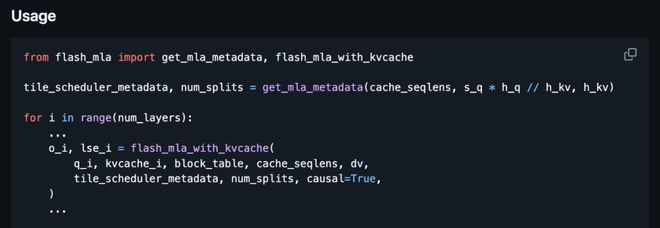
DeepSeek AI 也非常贴心地给出了快速上手指南,只需简单几步,就能体验 FlashMLA 的强大!
安装:
python setup.py install
复制
跑个 Benchmark 试试水:
python tests/test_flash_mla.py
GitHub 仓库传送门:https://github.com/deepseek-ai/FlashMLA
技术细节 & 引用
FlashMLA 的背后,离不开对FlashAttention 2&3以及cutlass等优秀项目的学习和借鉴。DeepSeek AI 在这些基础上进行了创新和优化,才有了今天的 FlashMLA。
温馨提示:FlashMLA 需要Hopper 架构 GPU、CUDA 12.3 及以上以及PyTorch 2.0 及以上版本支持哦! 使用前请确保你的环境满足要求!
⭐星标AI寒武纪,好内容不错过⭐
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
