




性能方面,和去年发布的GB200相比,推理性能是其1.5倍。

据悉,GB300将在今年的下半年出货。
除此之外,老黄还预览(2026年下半年发货)了英伟达下一代AI超级芯片,名字大变样——Vera Rubin。

其实它的命名规则和Grace Blackwell(GB)类似:Grace是CPU,Blackwell是GPU。
而Vera Rubin中的Vera是CPU,Rubin是GPU。根据老黄的说法:
几乎所有细节都是新的。
从预览的性能来看,Vera Rubin整体性能更是GB300的3.3倍。更具体一些:
- Vera:CPU的内存是Grace的4.2倍,内存带宽是Grace的2.4倍。
- Rubin:将配备288GB的HBM4。
在Vera Rubin之后的下一代GPU(2027年下半年),英伟达会将其命名为Rubin Ultra,性能直接拉到GB300的14倍。

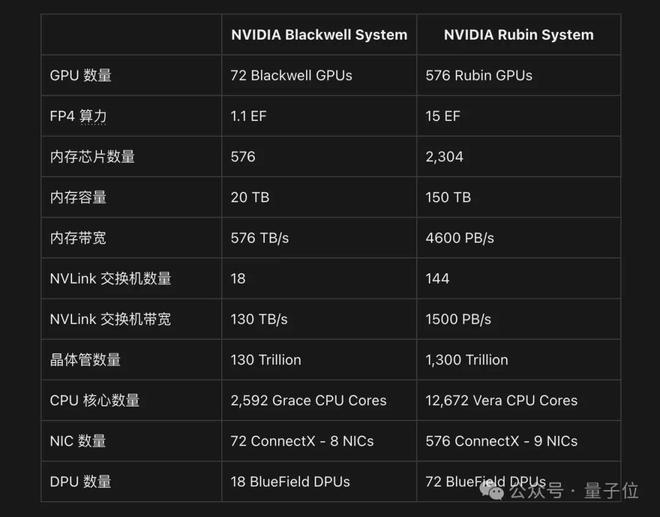
一个直观的对比,如下图所示:

更多的具体性能对比,是这样的:
性能上的提升,也正应了老黄在现场说的那句话:
大规模推理是一种极限计算。
Inference at-scale is extreme computing.
不仅如此,就连Rubin之后的下一代GPU,老黄也给亮出来了——将以Feynman来命名。

而纵观整场GTC,我们可以轻松提炼老黄提及最多的几个关键词:tokens、推理和Agentic AI。
但除此之外,还有一个比较有意思的关键词——DeepSeek。
英伟达官方博客称:
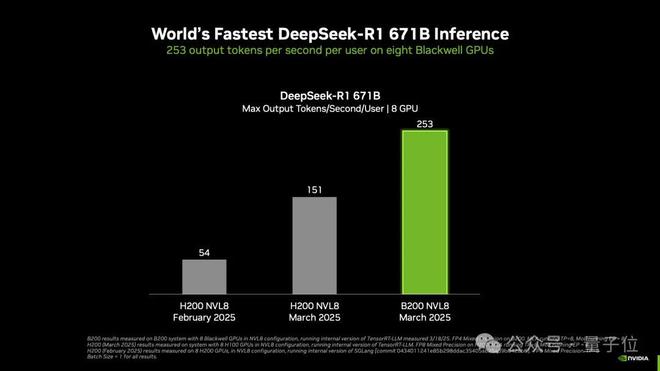
实现了DeepSeek-R1推理性能世界纪录。
每个用户每秒可处理超过250个token;实现每秒超过30000个token的最大吞吐量。
但这项纪录采用的是B200,英伟达表示随着Blackwell Ultra等新GPU的出现,纪录还将继续被打破。
而老黄在现场体现传统LLM和推理LLM的区别时,也是拿着DeepSeek-R1来举例:

嗯,微妙,着实有点微妙。
那么除了一系列新GPU之外,还有什么?我们继续往下看。
推出两款个人AI超级计算机
首先,第一款个人AI超级计算机,叫做DGX Spark。
它就是老黄在今年1月份CES中发布的那个全球最小的个人AI超级计算机Project Digits,这次取了个正式的名字。
DGX Spark售价3000美元(约21685元),大小和Mac Mini相当。
它采用的是英伟达GB10芯片,能够提供每秒1000万亿次的AI运算,用于微调和推理最新AI模型。
其中,GB10采用了NVLink-C2C互连技术,提供CPU+ gpu的相干内存模型,带宽是第五代PCIe的5倍。
值得一提的是,英伟达官网已经开发预定了哦~
至于第二款个人AI超级电脑,则是DGX Station。

DGX Station所采用的,正是今天推出的GB300,也是首个采用这款芯片的AI电脑。
其性能如下:
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
