




就在中国模型 DeepSeek 对 ChatGPT 领导地位发起挑战的一周后,OpenAI 终于做出回应,正式发布了其最新的推理模型 o3-mini。

图 | OpenAI CEO 奥特曼宣布 o3-mini 发布(来源:X)
更值得关注的是,这是该公司首次向免费用户开放最新的推理模型。这也是 AI 领域激烈竞争的真实写照:中国公司在 1 月 20 日发布的 DeepSeek R1 模型,以其惊人的性能和极低的成本引发了美国 AI 行业震动。
如果说 OpenAI 可能早就定好了模型发布日期,DeepSeek 半路杀出是出乎意料的,那么其定价或许在一定程度上受到了后者的影响:o3-mini 的定价是 1.10 美元/百万输入 token,4.40 美元/每百万输出 token。
这个价格比 OpenAI o1-mini 便宜了 63%,比完全体 o1 便宜 93%,可谓是“骨折价”。当然,定价还是比 DeepSeek 贵了很多(0.14 美元/百万输入 token,0.55 美元/百万输出 token)。

图 | o3-mini 定价(来源:OpenAI)
OpenAI 表示,作为小型模型系列中的最新成员,o3-mini 在科学、数学和编程等 STEM 领域表现出色。与其前辈 o1-mini 相比,它不仅保持了低成本运行的优势,而且在响应速度上也实现了显著提升。
o3-mini 的训练过程融合了公开数据和 OpenAI 内部开发的专有数据集。
为了满足不同场景的需求,o3-mini 创新地提供了低、中、高三种不同级别的“推理强度选项”,让用户可以根据具体任务灵活调整速度和准确度之间的平衡。
即便是在最低推理级别下,o3-mini 在数学和编程基准测试中的表现也能与 o1-mini 相媲美。而当设置为最高推理级别时,其表现甚至能够超越功能更全面的 o1 模型。

图 | LiveBench 编码:OpenAI o3-mini 在中等推理强度下超越了 o1-high,凸显了其在编码任务中的效率。在高推理强度下,o3-mini 进一步扩大领先优势,在关键指标上实现了显著增强的性能。(来源:OpenAI)
从具体数据来看,o3-mini 的表现确实令人印象深刻。测试人员反馈显示,与 o1-mini 相比,o3-mini 将重大错误率降低了 39%,其回答的受欢迎程度提高了 56%。
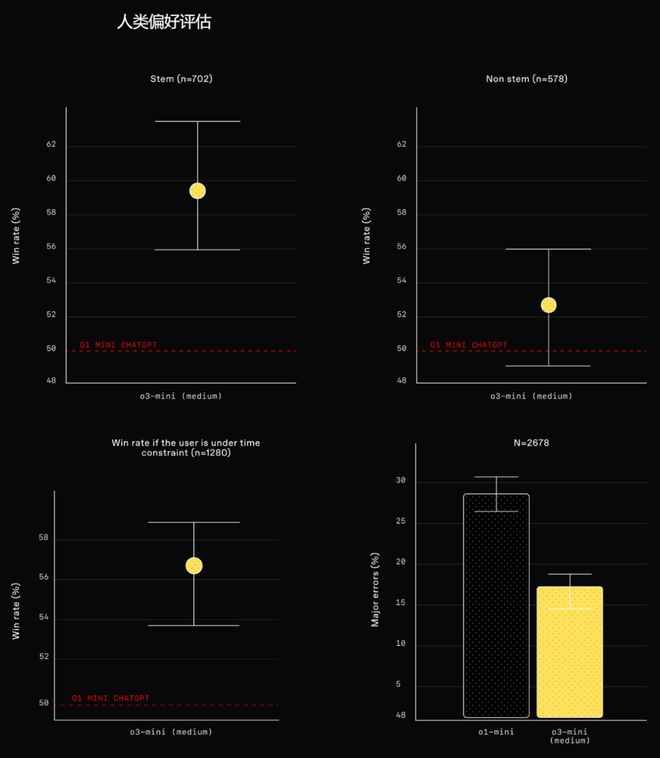
图 | 人类偏好评估(来源:OpenAI)
“外部专家测试人员的评估还表明,OpenAI o3-mini 的答案更准确、更清晰,推理能力比 OpenAI o1-mini 更强,尤其是在 STEM 方面。”OpenAI 写道。
即便在中等推理级别下,o3-mini 的平均响应时间也从 o1-mini 的 10.16 秒缩短到了 7.7 秒,提速达 24%。
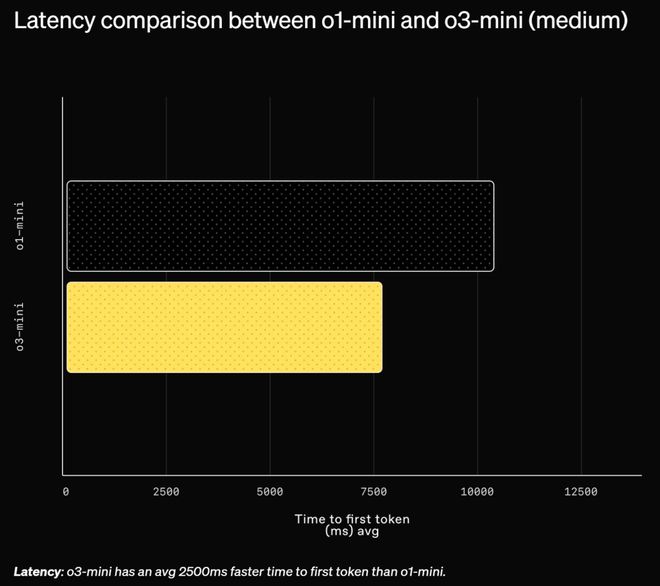
图 | 中等推理强度下,o1-mini 与 o3-mini 之间的延迟比较(来源:OpenAI)
在具体评估中,o3-mini 在多个领域都展现出了不错的表现。
在 2024 年 AIME 竞赛数学题目中,高强度推理模式下的准确率达到了 83.6%。在博士级别的科学问题测试中,其准确率也达到了 77%。
在软件工程方面,o3-mini 成为了目前表现最好的模型。此外,在代码竞赛平台 Codeforces 上,o3-mini 也取得了超过 2000 的等级分,展现出了强大的编程能力。
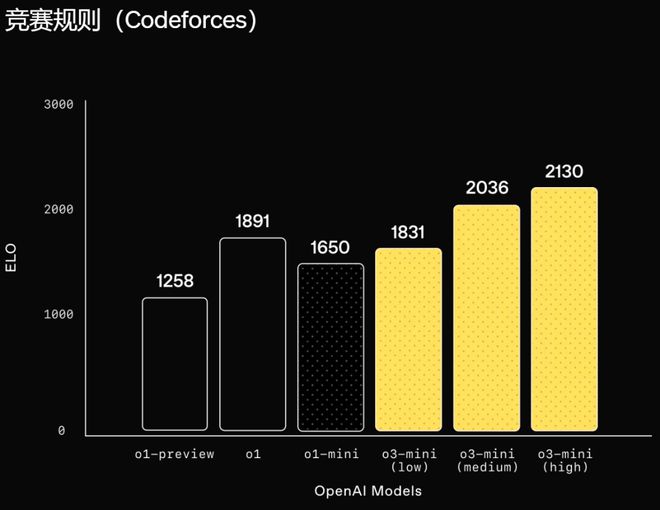
图 | 竞赛编程:在 Codeforces 竞赛编程中,OpenAI o3-mini 随着推理强度的提升而获得越来越高的 Elo 分数,均优于 o1-mini。在中等推理强度下,它的表现与 o1 相当。(来源:OpenAI)
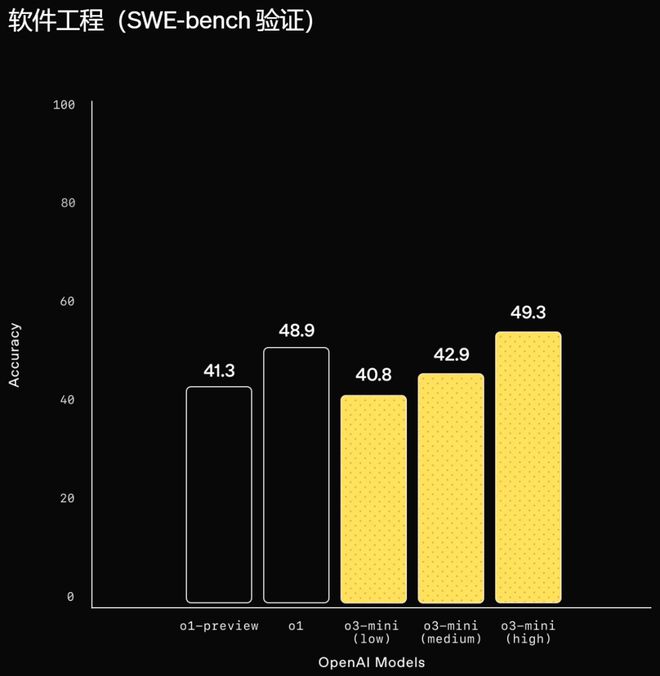
图 | 软件工程 SWE-bench 验证(来源:OpenAI)
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
