




奥特曼罕见地承认了自己犯下的「历史错误」,LeCun发文痛批硅谷一大常见病——错位优越感。DeepSeek的终极意义在哪?圈内热转的这篇分析指出,相比R1,R1-Zero具有更重要的研究价值,因为它打破了终极的人类输入瓶颈!
DeepSeek再度创造历史。
居然能逼得OpenAI CEO奥特曼承认:「我们在开源/开放权重AI模型方面,一直站在了历史的错误一边。」
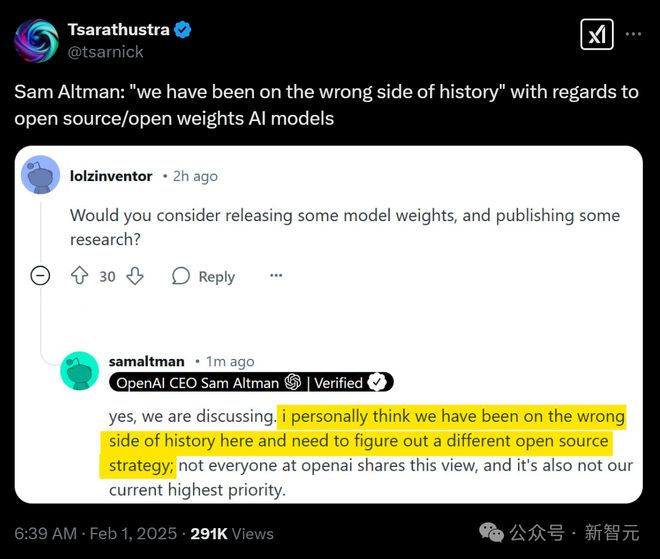
LeCun也发文指出,硅谷圈子的常见病,就是一种错位的优越感。
高级阶段的症状,是认为小圈子就能垄断好的想法。而晚期症状就是,假设来自他人的创新都是靠作弊。
DeepSeek的最大意义在哪里?
ARC Prize联合创始人Mike Knoop发出长文中总结道——R1-Zero打破了最终的人类输入瓶颈——专家CoT标注!其中一个例子,就是监督微调(SFT)。
从R1-Zero到AGI,一切都与效率有关。
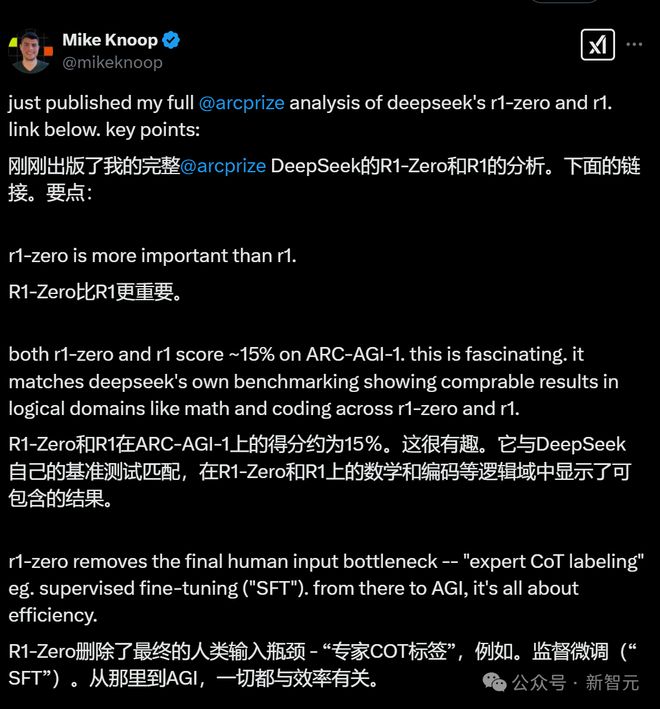
另一个值得注意的观点就是:相比R1,R1-Zero具有更重要的研究价值。
这是因为,R1-Zero完全依赖强化学习(RL),而不使用人类专家标注的监督微调(SFT)。
这就表明,在某些领域,SFT并非实现准确清晰CoT的必要条件,完全有可能让AI通过纯粹的RL方法实现广泛推理能力。
以下为Mike Knoop的完整分析。
从此,推理计算需求激增
上周,DeepSeek发布了他们新的R1-Zero和R1「推理」系统,在ARC-AGI-1基准测试上的表现可与OpenAI的o1系统相媲美。
R1-Zero、R1和o1(低算力模式)都取得了15-20%的得分,而GPT-4o仅为5%——而这已是多年纯LLM scaling的巅峰成果。
根据本周美国市场的反应,公众也开始理解了纯LLM scaling的局限性。
然而,大多数人仍没有意识到推理计算需求即将激增的问题。
2024年12月,OpenAI发布了一个新的突破性系统o3,经过验证,该系统在低算力模式下得分76%,高算力模式下得分88%。
o3系统首次展示了计算机在面对全新、未知问题时进行适应的通用能力。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
