




【新智元导读】AI界「智商大考」ARC-AGI-2重磅出炉了!一个人类用5分钟轻松解开的谜题,却让最顶尖LLM全线崩盘得分挂零,o3更是从曾经76%暴跌至4%。它正式宣告,人类还未实现AGI。
时隔6年,ARC-AGI-2正式推出!
一大早,Keras之父François Chollet官宣了全新迭代后的ARC-AGI-2,再次拉高了AI「大考」的难度。

这些对人类再简单不过的题目,LLM最先败北,先上结果:
基础大模型(GPT-4.5、Claude 3.7 Sonnet、Gemini 2 ),全部得0分。
CoT推理模型(Claude Thinking、R1、o3-mini),得分也不过4%。
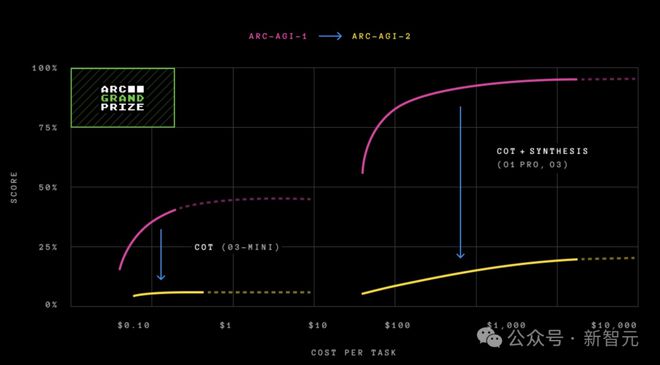
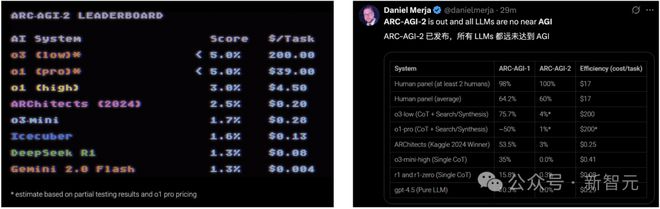
相较之下,2024年ARC Prize冠军模型(53.5%)却在新版本考试中,成绩仅剩3.5%。
OpenAI的o3-low模型也从75.7%骤降至4%。而且,每项任务成本效率也是o3-low和o1-pro最高,达到200美金。
相反,在ARC-AGI-2里的每个任务,都至少有两名人类能在两次尝试内成功解决。
ARC-AGI-2的出世,证明了「人类尚未实现AGI」!

现场400人实测,普通人无训练能拿下60%准确率,10人小组能达到100%
初代ARC-AGI(2019年),曾在去年揭示了AI重大转变,LLM从「纯记忆」向「测试时推理」的进化。
许多之前一眼就看透的问题,在ARC-AGI-2中,至少需要几分钟的深思熟虑——人类测试者平均需要5分钟才能解题。
最新ARC-AGI-2,恰恰暴露了当前AI三大短板:符号解释、组合推理、上下文规则应用。
这些皆需要LLM在测试时,展现真正的适应能力,具备灵活应对新问题的「流体智力」,而不是靠预训练数据「硬背」过关。
值得一提的是,2025年ARC奖本周将在Kaggle平台上线,总奖金高达100万美元。
今年的竞赛在去年基础上再加码,计算资源翻倍,旨在推动开源项目发展,助力打造能战胜ARC-AGI-2的系统。
AI「大考」难度进阶,AGI梦碎?
其他AI基准测试,基本都聚焦于测试「博士以上水平」的技能,来考察超越人类的能力或专业知识。
但ARC-AGI关注的是对人类相对容易,对AI却困难重重的任务。
这样一来,就能精准定位那些不会因为规模扩大就自动消失的能力差距。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
