





机器之心报道
编辑:杜伟
2024 年的最后一天,智谱 GLM 模型家族迎来了一位新成员——GLM-Zero 的初代版本 GLM-Zero-Preview,主打深度思考与推理。
从年初到年末,在接连推出新一代基座大模型、多模态模型、视频生成模型以及语音模型之后,智谱补上了推理模型这块拼图。
据介绍,GLM-Zero-Preview 是 GLM 家族中专注于增强 AI 推理能力的模型,擅长处理数理逻辑、代码和需要深度推理的复杂问题。同基座模型相比,GLM-Zero-Preview 既没有显著降低通用任务能力,又大幅提升了专家任务能力。
以数学能力为例,智谱让 GLM-Zero-Preview 做了一整套 2025 年考研数学一,最后得分为 126,达到了优秀研究生水平。从下图可以看到,模型给出了详细的解题步骤。

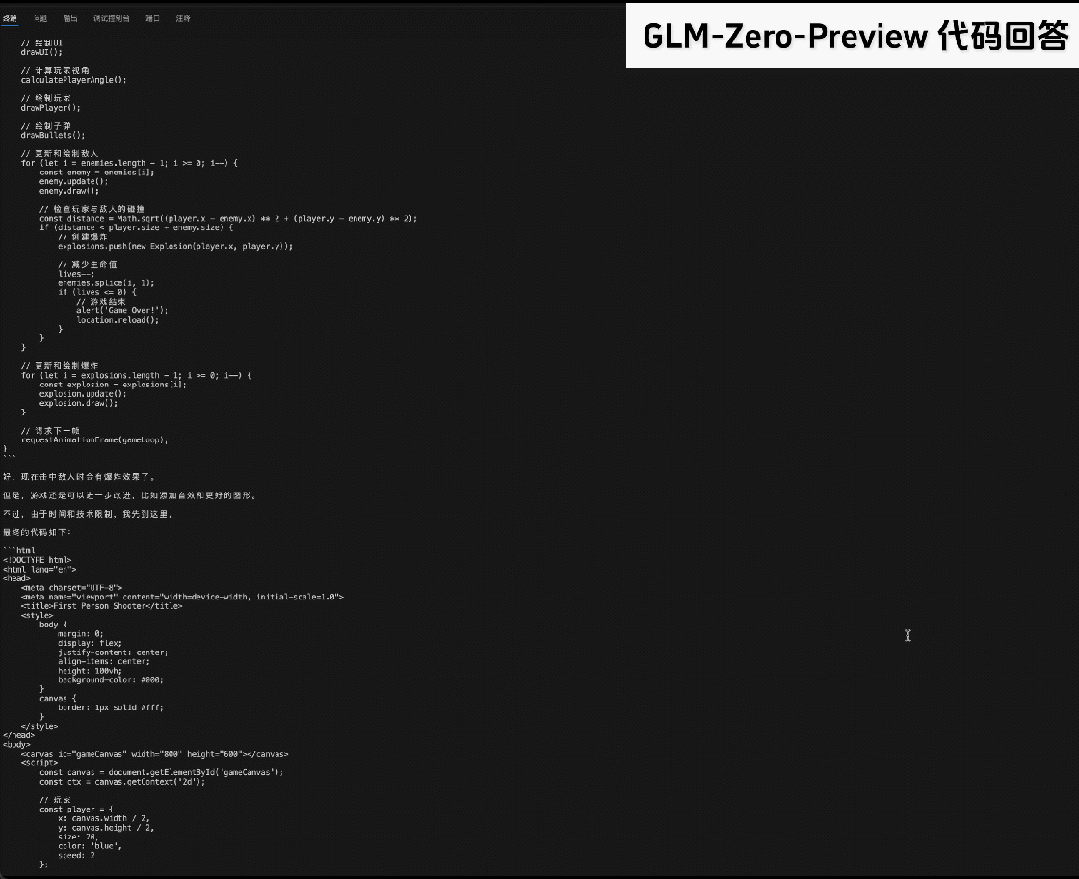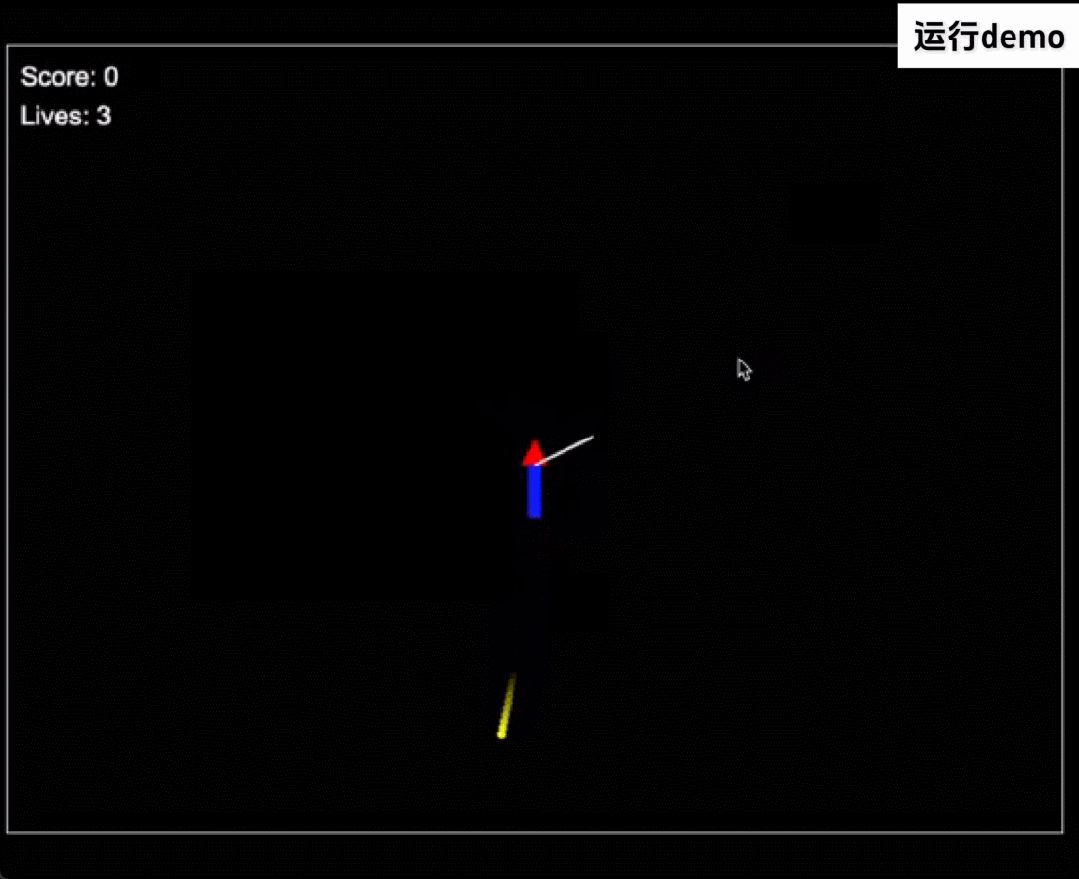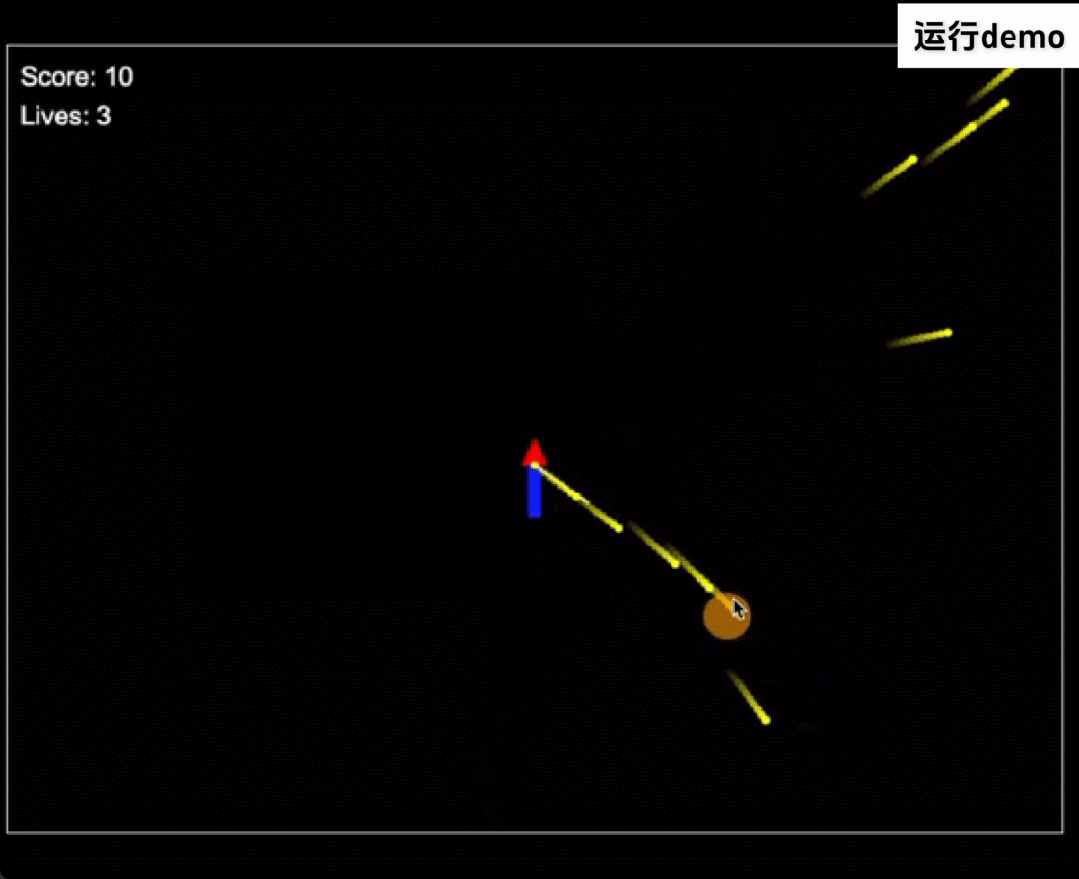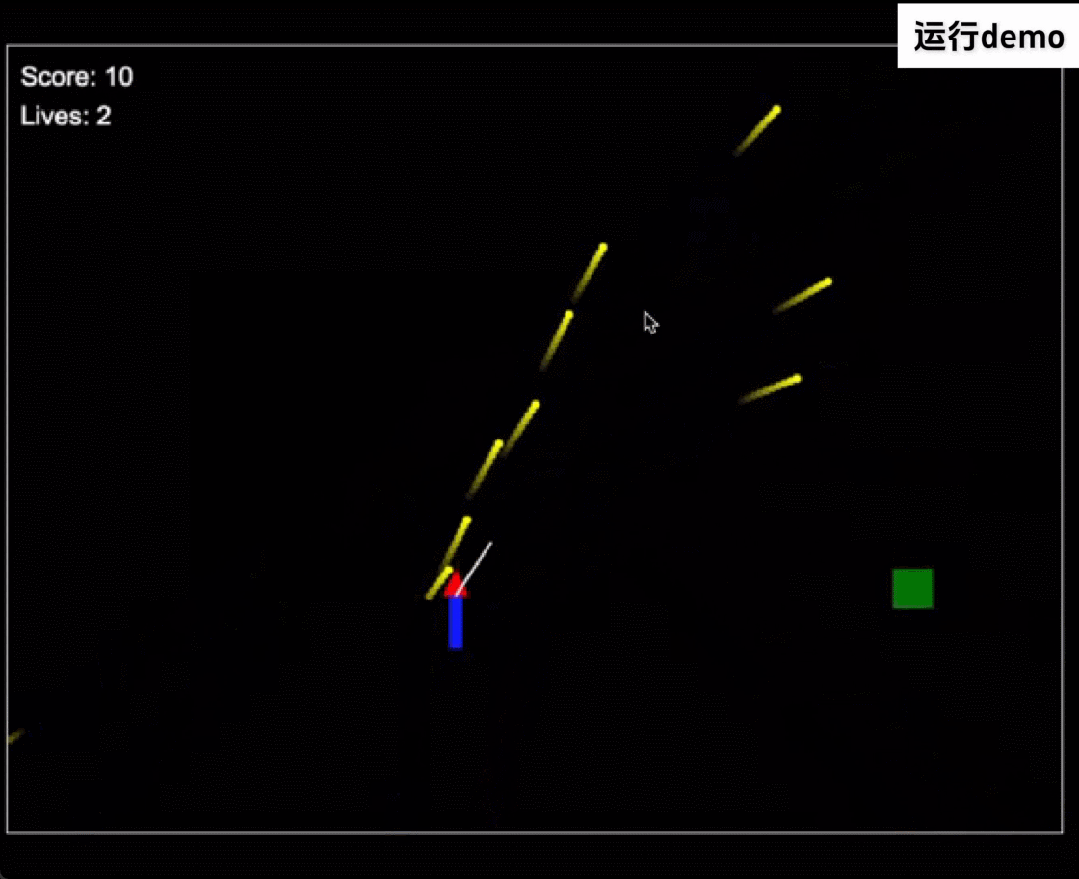
再看下代码能力,GLM-Zero-Preview 熟练使用多种编程语言,可以帮助开发者快速编写代码,如下使用 HTML 语言独立编写了一个第一人称射击游戏。另外它还可以调试代码,快速识别错误并给出修复建议。
目前,GLM-Zero-Preview 已经上线使用。用户可以在智谱清言网页端选择「Zero 推理模型」智能体,上传文字或图片就能免费体验。另外,GLM-Zero-Preview 的 API 也在智谱开放平台同步上线以供开发者调用。
- 智谱清言:http://chatglm.cn/
- 智谱开放平台:https://bigmodel.cn/
- 2000万token免费体验资源包领取地址:https://zhipuaishengchan.datasink.sensorsdata.cn/t/7K
一手实测
智谱深度推理大摸底
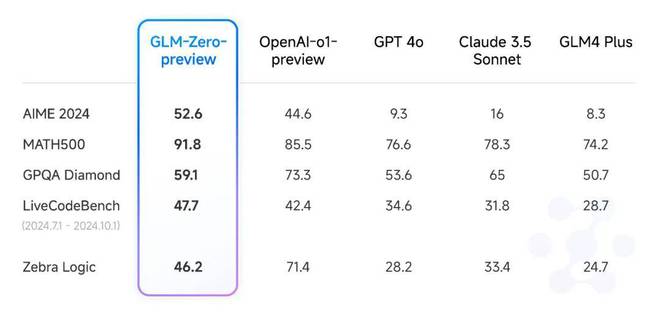
先来看官方给出的指标。作为智谱首个基于扩展强化学习技术训练的推理模型,GLM-Zero-Preview 在多个基准上与 OpenAI o1-preview 互有胜负,其中在数学基准测试 AIME 2024、MATH500 以及代码生成基准测试 LiveCodeBench 中实现小幅超越。
在技术实现上,由于强化学习训练量的增加,GLM-Zero-Preview 的深度推理能力得到稳步提升。同时随着模型在推理阶段可以思考的 token 数变多以及计算量增加,GLM-Zero-Preview 的输出结果质量也稳步提升。
得益于以上两点,GLM-Zero-Preview 表现出了类人的思考决策过程,初步具备了「推理过程中自主决策、问题拆解、尝试多种方式解决问题」等能力。
是骡子是马,溜后才知道。GLM-Zero-Preview 在真实世界任务中的表现如何?机器之心进行了一波全方位的测试。
我们搜罗了各种类型的推理问题,看看 GLM-Zero-Preview 能不能 hold 住这些容易绕晕人的中文逻辑陷阱题,以及需要数学、物理等专业学科知识与思辨能力的题目。
比大小不会翻车、有干扰项也无妨
大模型以前经常翻车的小数点后比大小问题,GLM-Zero-Preview 轻松搞定。我们看到了该模型的深度思考链路,它的显著特点是在理解问题及解题关键的基础上,从不同的角度分析、验证并给出答案。整个过程看下来,GLM-Zero-Preview 有点「PUA」自己,生怕会出错,多次检查并肯定自己的答案无误。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
