




GRPO训练又有新的工具链可以用,这次来自于ModelScope魔搭社区。
随着DeepSeek-R1的成功出圈,其使用的GRPO算法受到了业界的广泛关注。GRPO训练是来自于PPO算法的一种改进,旨在利用采样原理对value model进行简化,以增大训练的稳定性和可维护性。
目前围绕R1模型的技术方案,社区也已经有一些开源实现,比如来自Hugging Face的Open-R1,以及其他一些RL框架,包括veRL,OpenRLHF等等。然而,在GRPO训练方面,大部分方案仍然面临着诸多挑战,包括训练速度较低、集群配置复杂,以及对多模态扩展能力差、训练后不好评测等等。
为了支持开源社区在GRPO这个方向上的探索,ModelScope魔搭社区围绕MS-SWIFT训练框架以及EvalScope评估框架,推出了相对完整高效的GRPO全链路解决方案,和社区分享。
GRPO训练提速
GRPO训练的耗时主要来自于采样、训练等几个方面。其中,采样本身是PPO算法的重要组成部分。尤其是GRPO在PPO的基础上,使用采样代替value model的方案,这使得在GRPO训练中,采样的耗时的占比,更是大大的增加了。而且GRPO中单query的采样数(即group size),一般比较大(DeepSeekMath论文中为64个),高采样频率对于推理引擎的挑战是巨大的。优化采样效率是提升GRPO整体训练速度的核心所在。
基于这些特点,魔搭社区的SWIFT框架进行了有针对性的优化:
多实例数据并行采样
对于GRPO算法,单实例采样往往无法满足需求。团队观察发现,7B模型在训练期间,单iter的采样时间占比约为70%,这意味着应该允许训练资源根据实际情况,针对性的倾斜分配给采样计算
尤其在采样量以及batch_size较大时,采样耗时对训练速度影响会更为显著。因此,在SWIFT中对vLLM和LMDeploy进行了一定的patch(同时也与相关框架负责同学进行了讨论,将会将相关实现在vLLM/LMDeploy上原生支持),支持在任意比例的训练卡上拉起采样实例。例如对于8卡训练中,配置4张卡负责模型训练,4张卡负责采样;或者6张卡负责训练,2张卡负责采样。
下图展示了在同样的8卡训练设置下,分别使用1卡/2卡部署推理引擎进行采样,剩余卡负责训练,vLLM/LMDeploy的采样耗时和训练耗时如下:
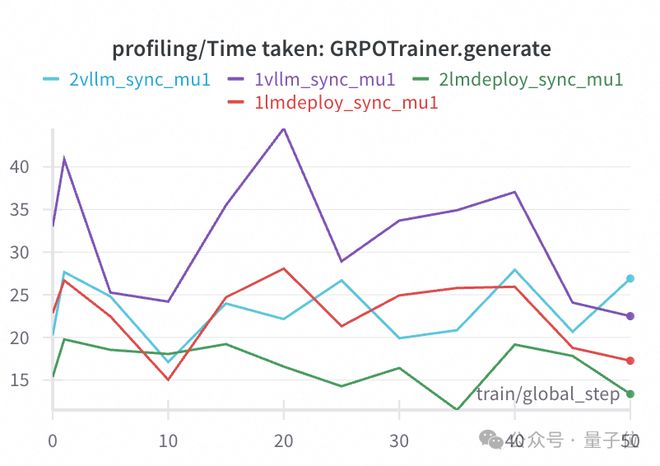
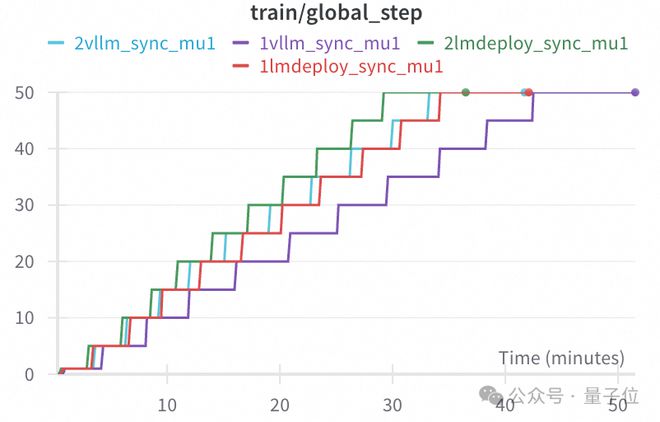
可以看到,基于LMDeploy分配2卡进行采样时,训练时长约为1卡采样的87%。而vLLM2卡采样时,时长为1卡采样的78%。在这两个例子中,通过更合理多卡数分配,对采样资源进行一定倾斜,都达到了有效降低训练所需时长都目的。
异步采样
GRPO训练中,采样和模型训练需要交替进行,即训练时采样卡闲置,采样时训练卡闲置。对于这个问题,不同的框架给出了不同的解决方案。
例如veRL允许将采样和训练部署在同一GPU上,在不同阶段让不同的权重offload到CPU中;或者针对LLM的不同Layer、不同Tensor进行异构式切分,在加载权重时不必all_gather(而是部分weights进行gather并同步),使训练模型和采样模型的效率达到最高。然而在中小模型的体量上,这样的切分未必是最优的。
因为随着模型尺寸和batch_size增大,采样、训练的耗时占比会有本质差别。对此SWIFT采用了不一样的技术路线,即异步采样(replay buffer),其原理是在训练时同时进行采样,采样结果用于下一iter的模型训练。由于采样使用的是old policy model,因此训练过程需要额外增加对于logits差异的CLIP。由于old policy model和policy model仅相差一个iter,因此其训练稳定性几乎没有下降。二者唯一需要等待(或者stop the world)的过程是权重加载。
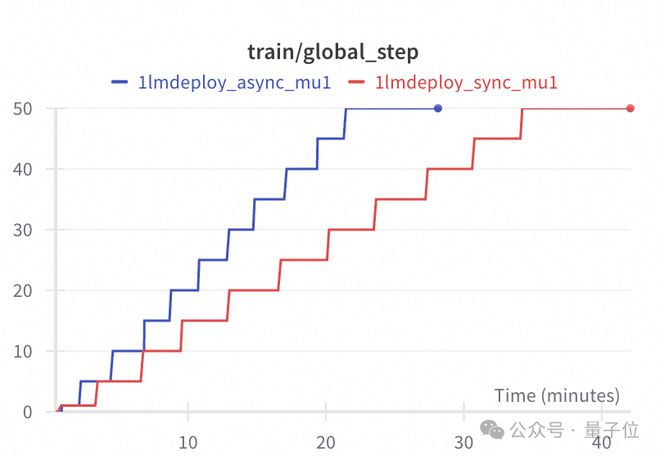
同样训练设置下的实验测试表明,在单卡部署LMDeploy的情况下,异步采样的训练时间约为同步采样的2/3。
模型placement
SWIFT除了支持上述训练和rollout使用两个资源组进行异步训采流程之外,也支持二者共用同一资源组。即,在actor模型训练时,vLLM将开启sleep模式以减少显存占用。
这两种模式的架构图如下:
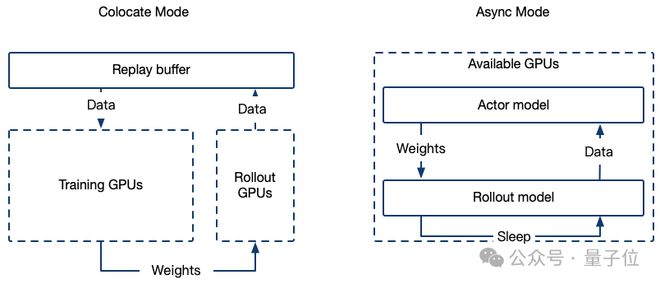
并且,SWIFT也支持vLLM的tensor_parallel(MP)模式。
LMDeploy推理框架支持
LMDeploy是来自于上海浦江实验室的优秀推理加速框架。该框架不仅支持了纯文本和多模态模型的推理加速,并且自研了基于FasterTransformer实现的Turbomind推理加速引擎。在推理速度上,LMDeploy相较vLLM在一众模型上速度有显著的提升。对Qwen2.5-7B-Instruct模型进行实验测试,具体配置如下:使用AI-MO/NuminaMath-TIR数据集,批量大小设置为7,每条query采样24条结果,训练50个steps。以下是vLLM框架和LMDeploy框架在相同条件下的推理时长对比。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。
